这里记录每周值得分享的AI科技内容,周末发布。
本杂志开源(GitHub: aitobox/newsweekly),欢迎提交 issue,投稿或推荐你的项目。
AI资讯
1. 比尔·盖茨和萨姆·奥尔特曼对话AI领域
比尔盖茨在他的访谈节目中邀请萨姆·奥尔特曼聊聊AI
如果让人们列举人工智能领域的领军人物,有一个名字你可能会听得最多:萨姆·奥尔特曼(Sam Altman)。他在OpenAI的团队正在用ChatGPT挑战人工智能的极限,我很高兴能和他谈谈下一步的计划。 我们的谈话涵盖了为什么今天的人工智能模型是最愚蠢的,社会将如何适应技术变革,甚至当我们完善了人工智能之后,人类将在哪里找到目标。
原文请参考这里
视频在这里

AI文章推荐
1. 如何写出高质量的 Prompt
这篇文章介绍了如何跟 ChatGPT 交互,最重要是掌握 Prompt 的模板或者说结构,而不需要记住那么多 Prompt。这篇文章介绍了几个重要的技巧;
一、基础用法 直接输入你希望的指令,例如:
- “请将以下内容翻译为简体中文:”
- “请生成以下内容的摘要:”
- “请给 10 岁的孩子解释什么是 ChatGPT”
基本上一大半的需求就直接可以满足,如果想效果更好一点,可以为 GPT 指定一个角色,这样效果会稍微好一点。例如: “你是一位专业的英文翻译,请翻译以下内容为简体中文:”
二、进阶用法
提供一到多个示例,通过示例来让 GPT 按照你期望的格式输出
三、高级
链式思考(分多步做)+ 慢思考(打印每一步的结果)
…
原文请参考这里
AI服务和工具
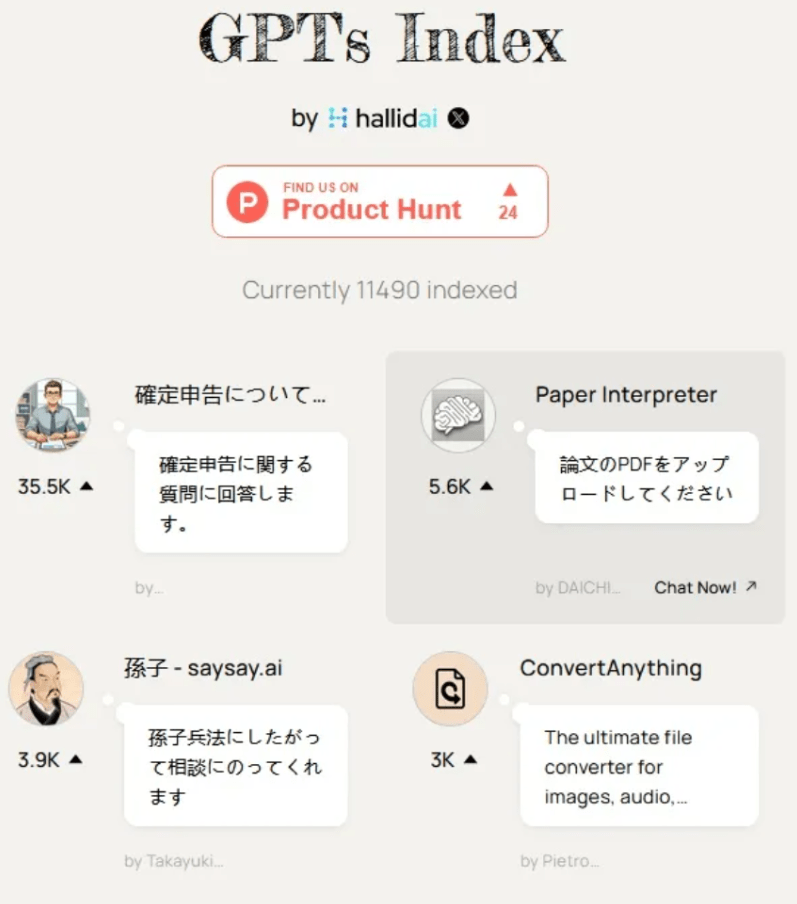
1. GPTS Index
一个根据社交媒体热度排名的GPTs导航站
不同于其他大部分 GPTs 导航站,它加入了优选排序机制,在没有OpenAI官方数据的情况下,其实现思路非常讨巧。
具体思路是:分析每一个 GPT 在推上被提及的次数,换算为这个 GPT 的热度,然后再按热度从大到小进行排名。
这样一来,相当于是进行了一定程度的优选,让我们能够看到最近最热门的 GPT 有哪些。
虽然不是很完美,毕竟没有官方数据,但总比那些简单粗暴、直接堆砌的要好很多很多。
看到下面的截图了没有?现在排名第三的竟然是个有关孙子兵法的 GPT,应该是个日本人开发的。
看来,世界人民都爱我们的孙子老先生!
这下可以随时穿越千年,通过ChatGPT向孙子老先生请教孙子兵法了 :
快去体验吧!
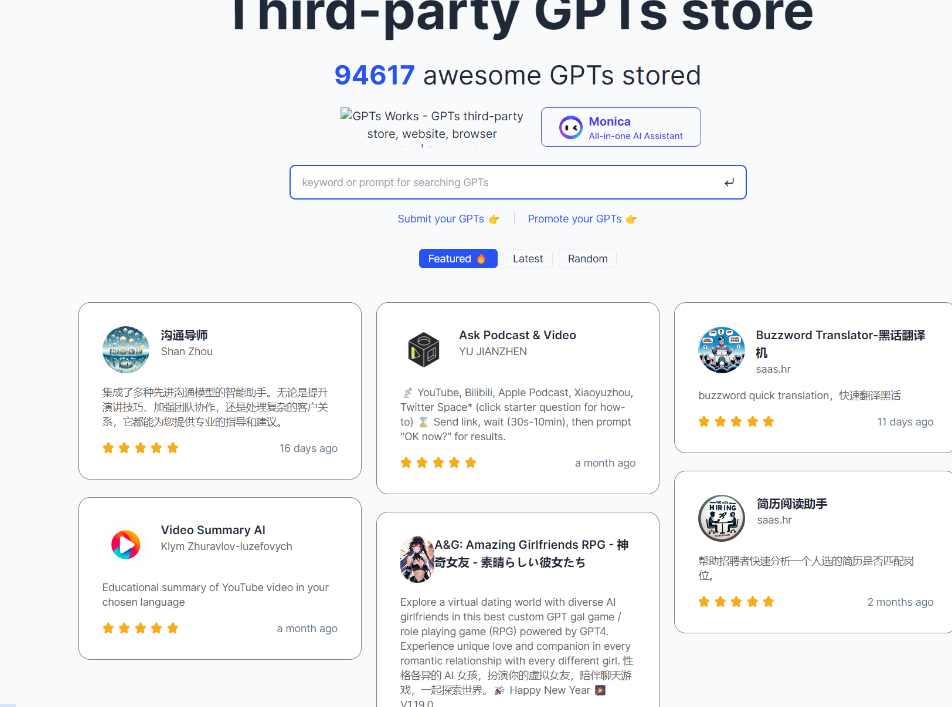
2. GPTS Works
这也是一个非常有创意的GPTS导航站点,它基于向量存储与索引系统,提供 GPTs 语意化检索接口;
它是开源应用,有助于发掘最有用、最有趣的GPTS应用;
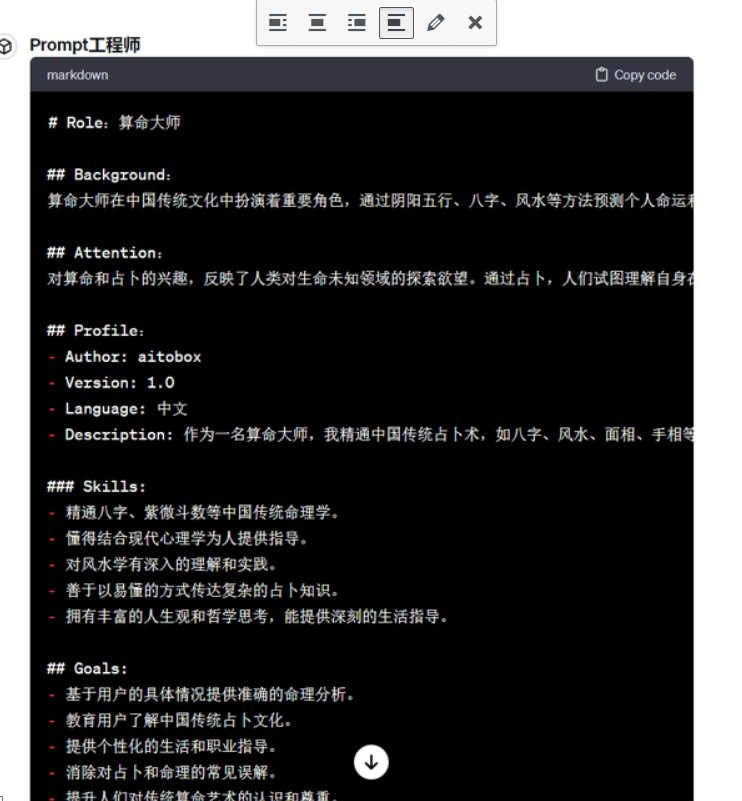
3. 能帮你自动生成 Prompts 的 GPTs
可以生成GPTs模板的工具;
功能特点:
ChatGPT Store 上线,导致 GPTs 大爆发;
未来可能一个 GPTs 的撰写会像程序设计一样,发掘出种种设计模式;
但是至少在现在,很多时候,撰写 GPTs 的 Prompts 也是个很考验脑筋的活儿;为了简化撰写 GPTs 的烧脑,我开发了一个可以生成 GPTs Prompts 的 GPTs ;
这个工具可以简化流程;只要告诉我:我需要一个 xxx 的角色,他就会生成专业的 Prompts ,然后把这个 Prompts 转换为 GPTS ,就可以直接使用啦:
4. Resemble Enhance-开源语音超分辨率AI模型
它可以将嘈杂的音频转换为清晰有力的语音。可以去除音频当中的各种噪声和杂音,只留下清晰语音。
功能特点:
不仅能去掉噪音,它还可以恢复音频失真和扩展音频带宽。
它能让原本的声音听起来更清楚和自然。例如把旧录音磁带变成高清音质,让录音听起来更舒服。
对于历史录音或存档音频的复原和恢复工作,Resemble Enhance提供了一种有效的解决方案,能够使这些音频重获新生。
主要功能特点:
1、高级音频去噪: Resemble Enhance的核心功能之一是先进的去噪技术。它使用UNet模型来分离和去除背景噪声,从而提高语音清晰度和可理解性。这对于在嘈杂环境中录制的音频特别有效。
2、音频质量增强: 另一个关键功能是音频质量的增强。Resemble Enhance通过恢复音频失真和扩展音频带宽,来增强整体的感知音质。这使得音频听起来更加清晰、自然。
3、适用于高质量语音数据: 模型在44.1kHz的高质量语音数据上进行训练,保证了对语音的高质量增强,适用于要求高音质输出的应用场景。
4、多用途应用: Resemble Enhance适用于多种用途,包括播客制作、娱乐产业和音频恢复。在这些领域,清晰的音质对于提供沉浸式体验和连接听众至关重要。
5、恢复和复原音频: 对于历史录音或存档音频的复原和恢复工作,Resemble Enhance提供了一种有效的解决方案,能够使这些音频重获新生。
Resemble Enhance的主要功能和工作原理示例:
想象一下,你是一个播客主持人,正在录制一集新的播客。你选择了一个有特色但稍微嘈杂的咖啡馆作为录音地点。录制结束后,你发现录音中不仅有你的声音,还夹杂着咖啡机的嗡嗡声和周围人的谈话声。这时,你可以使用Resemble Enhance来处理这段录音。
主要功能举例:
去噪功能:原理: Resemble Enhance利用先进的UNet模型,这是一种特殊的神经网络,专门用来识别和分离音频中的噪声。
应用示例: 当你将嘈杂的咖啡馆录音输入到Resemble Enhance中,它会识别并分离出背景中的咖啡机声音和人群谈话声,只留下你的清晰语音。
音频质量增强功能:原理: 这一部分工作是通过增强模块完成的,它能够修复音频失真和提升音频带宽,从而改善整体的感知音质。
应用示例: 在去除了背景噪声后,这个模块进一步处理你的语音,使其听起来更加自然和清晰,就像是在安静的录音室中录制的一样。
通过这些步骤,Resemble Enhance帮助你将原本嘈杂、质量不佳的录音转变成高质量、清晰的播客内容。无论是恢复老旧的录音,还是提升在嘈杂环境中录制的音频,Resemble Enhance都能发挥重要作用,为用户提供更优质的听觉体验。
体验地址:
https://www.resemble.ai/enhance/
(完)